


LLMs (Large Language Models) have revolutionized the technology world over the past few years. All these LLMs are available in different configurations, some need high-end GPU instances while others can be used on smartphones. To meet your specific needs, you need to choose the right model, and sometimes need to fine-tune these models before they can be used for inference.
While working on a recent AI project for one of our clients, Blockscout, we had a requirement to choose and fine-tune an LLM. In the early days of this project, we faced problems with maintaining multiple fine-tuning configurations and evaluating the fine-tuning results like losses at different epochs, resource utilization, and other key metrics. The problem increased exponentially when the evaluation needed to be performed through multiple experiments on different LLMs.
Fine-tuning Challenges
- With multiple runs, it was becoming difficult for us to keep track of the configurations and hyperparameters (like number of epochs, learning rate, etc.), and so we started maintaining these along with other logs in a Google Sheet. It was a cumbersome process and led to numerous manual errors. There had to be an automated method that collects all the details and stores them in one place.
- The training_loss for each epoch was printed in logs and analyzing these was difficult as the number of epochs increased to 30. The best-fit model is produced by merging the base model with the epoch having the least training_loss; therefore, the ability to get insights into these trends through graphs was crucial.
- Each fine-tuning experiment took around 16-17 hours to complete. During one experiment, the fine-tuning failed at an intermediate stage due to an 'Out Of Memory' issue and the machine remained in an idle state for a long time. A real-time notification for such alerts would have helped us save both time and machine costs.
We discovered several tools that could help us navigate these challenges and decided to go with WandB after analyzing a few.
What is WandB?
In their words: “Weights & Biases (WandB) is a Platform that helps AI developers build better models faster. Quickly track experiments, version and iterate on datasets, evaluate model performance, reproduce models, and manage your ML workflows end-to-end.”
How did we use WandB?
- We integrated WandB into our workflow with a few simple steps. To log in to WandB, we called the
wandb.login()method with the access token. - To initialize a project on WandB, we used
wandb.init()which took project_name, run_name, and configuration as parameters. Using this, we were able to maintain configurations across multiple runs. This also helped us in reproducing a finetuned model with the same configurations at a future point in time.
wandb.init(project= project_name, name= run_name, config={training_params})- We passed the training results of each epoch to
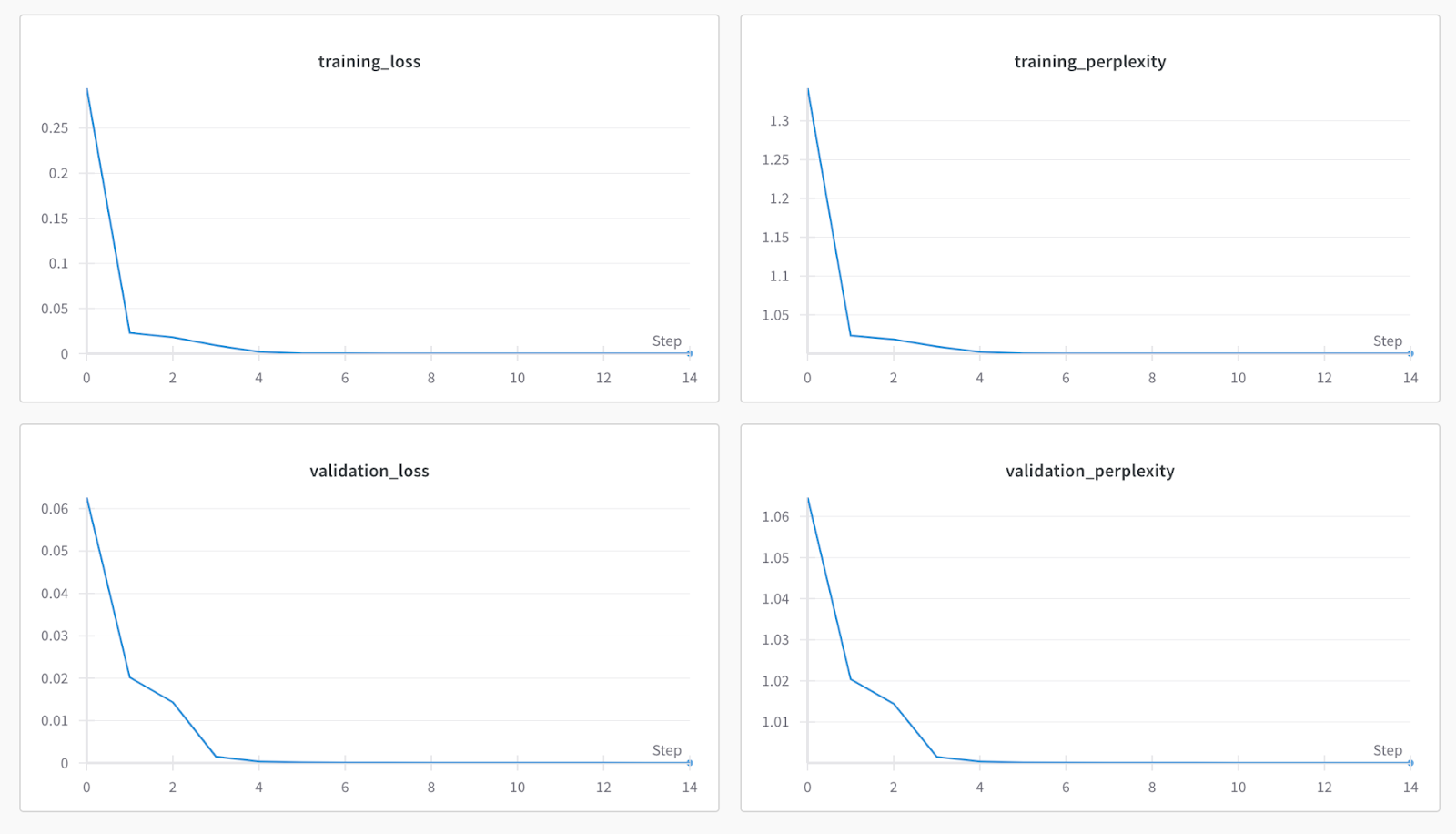
wandb.log()method which helped in visualizing the model results by plotting graphs for those results (shown in the image below). These graphs assisted us in assessing the model fit during fine-tuning and adjusting the hyperparameter values for upcoming training.
If the training_loss consistently decreased, it indicated that the model was learning effectively and was likely a good fit. Conversely, if the training_loss failed to decrease, the model may be under-fit, suggesting it hadn't learned the patterns well. On the other hand, if, after a certain epoch, the training_loss started increasing, forming a V-shape on the graph, it suggested overfitting i.e. the model has learned the training data too well but may struggle with new data.
wandb.log({"training_loss": training_loss,"training_perplexity": train_perplexity, "validation_loss": validation_loss, "validation_perplexity": validation_perplexity})
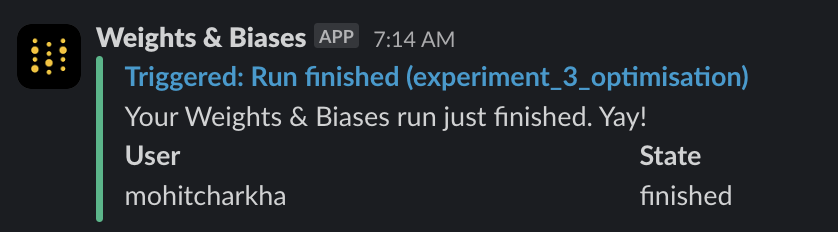
- WandB allowed easy integration with Slack for notifications related to the completion of fine-tuning or termination due to any error. We also used
wandb.alert()to send custom alerts after each epoch completion.
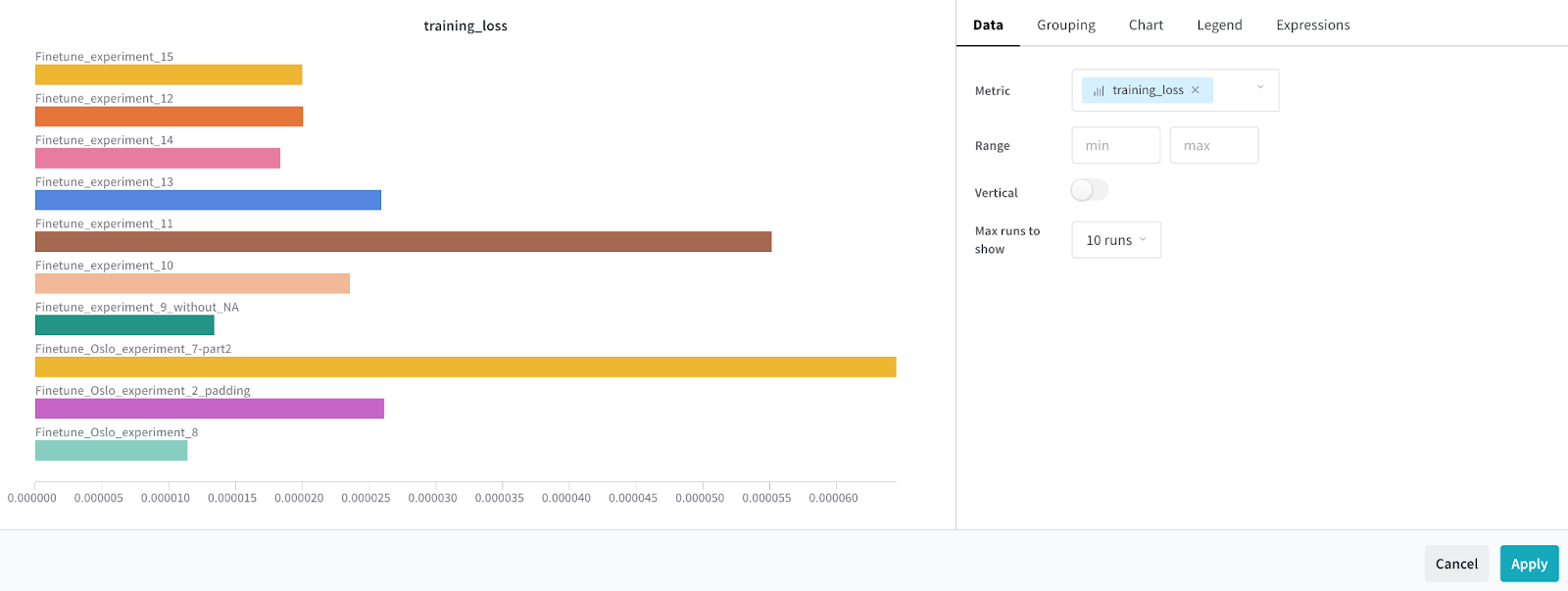
- Managing multiple runs within a single project helped us compare fine-tuning results and configurations across different runs and pick the best model based on the results.
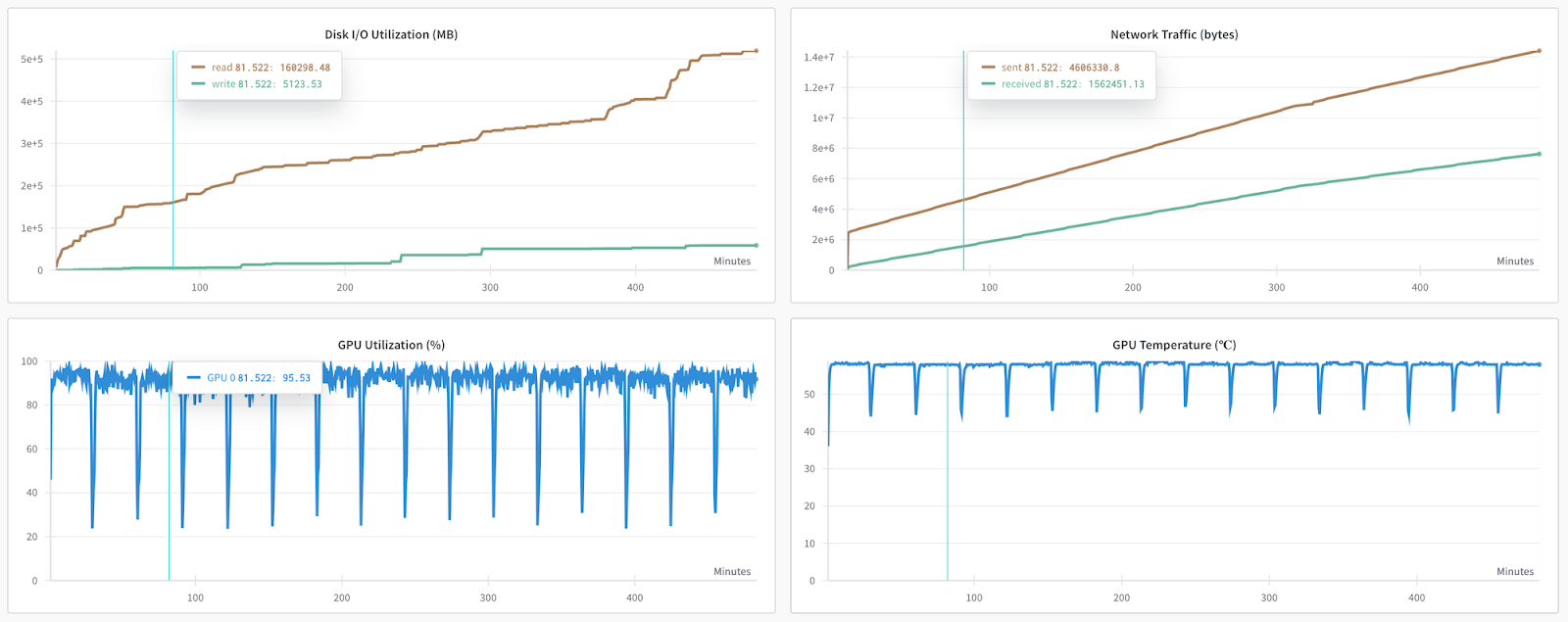
- WandB also provided charts for system metrics like GPU Utilization, Network Traffic, Memory usage, etc. which helped us manage device configurations for upcoming fine-tunings.
WandB addressed specific challenges that we faced while fine-tuning the model with minimal integration efforts. Btw, we used their free tier and that was sufficient for our needs.
What can we say? We have become WandB fanboys! It is a very useful platform that has grown into an essential part of our fine-tuning projects.



