


OpenAI and similar services have democratized access to AI, making it more accessible to everyone without worrying too much about the technical complexities of hosting and serving.
On the other hand, newer and more advanced models are developed and released on platforms like Hugging Face, allowing them to tackle specific problems more effectively and quickly. However, deploying these models requires considerable research and exploration into how to set them up on cloud servers because of the computational needs and large model size.
We dealt with this challenge firsthand in one of our recent client projects. The project required fine-tuning, evaluating the fine-tuned model, serving, and hosting of the Llama2 model.
Serving: Hugging Face Transformers vs vLLM
Hugging Face Transformers
Since we were using llama-recipes for fine-tuning experiments the inference script of llama-recipes was our primary choice for evaluation of fine-tuned models. The script uses the Transformers library by Hugging Face. We know that the inference time also depends on the token size. In our case, prompts consisted of an average of 660 tokens. The script took an average of ~10.5 seconds for inferencing on a 24 GB single GPU Machine. 😱
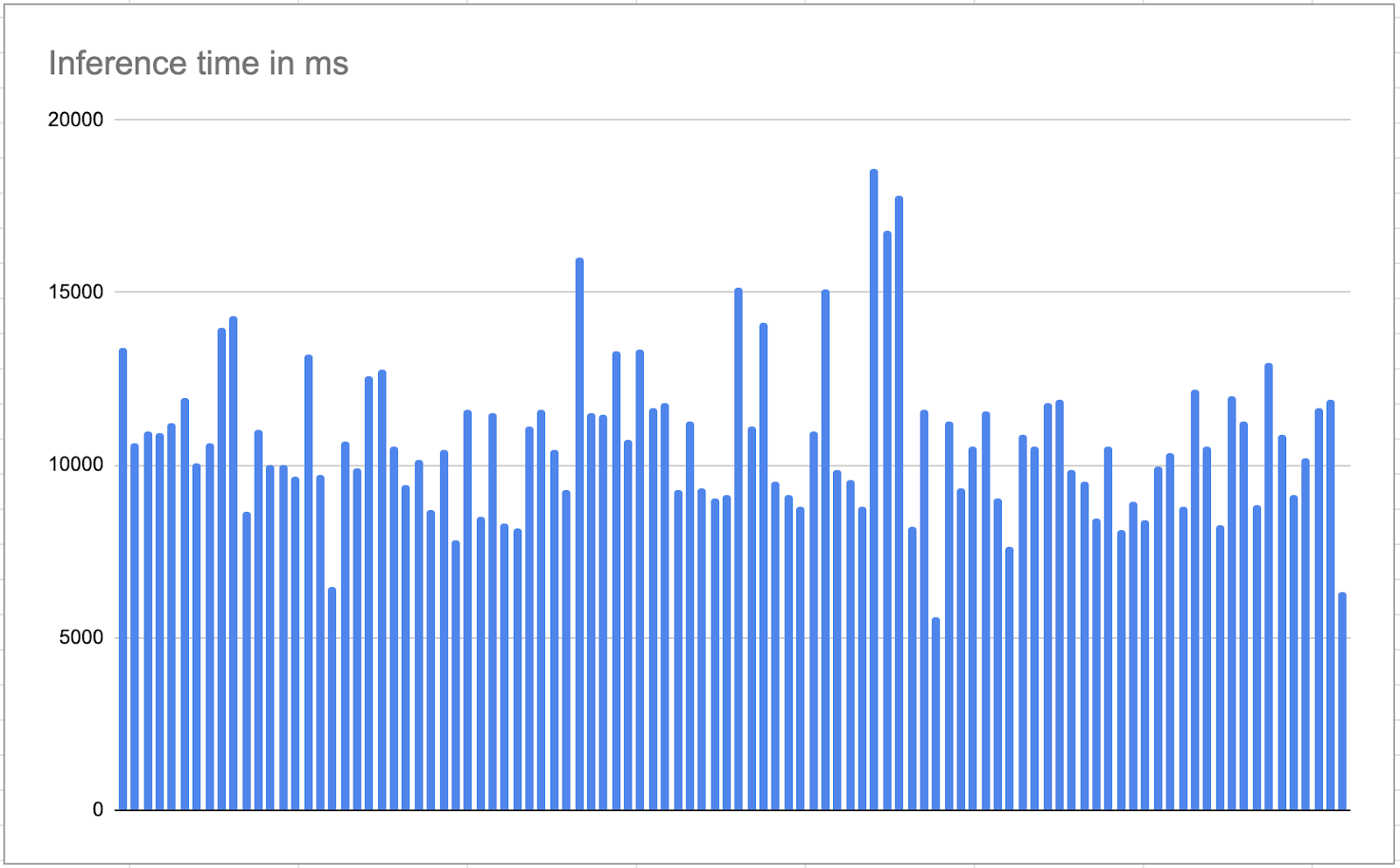
It was a no-brainer that we cannot use this code for inference on production.
We started looking out for alternative solutions to serve the model and came across the open-source vLLM library that claimed to achieve 24x LLM inference throughput than HuggingFace Transformers.
vLLM
vLLM is a fast and easy-to-use library that provides State-of-the-art serving throughput for LLM inference and serving. We replaced the Hugging Face Transformers Library with vLLM in our fine-tuned model evaluation script. vLLM reduces the inference time by efficient memory management, optimized Cuda kernels & various other optimization techniques. The script took an average of ~200 milliseconds for inferencing on the same 24 GB single GPU Machine. Hence achieved speed gains of up to 50x. 🕺
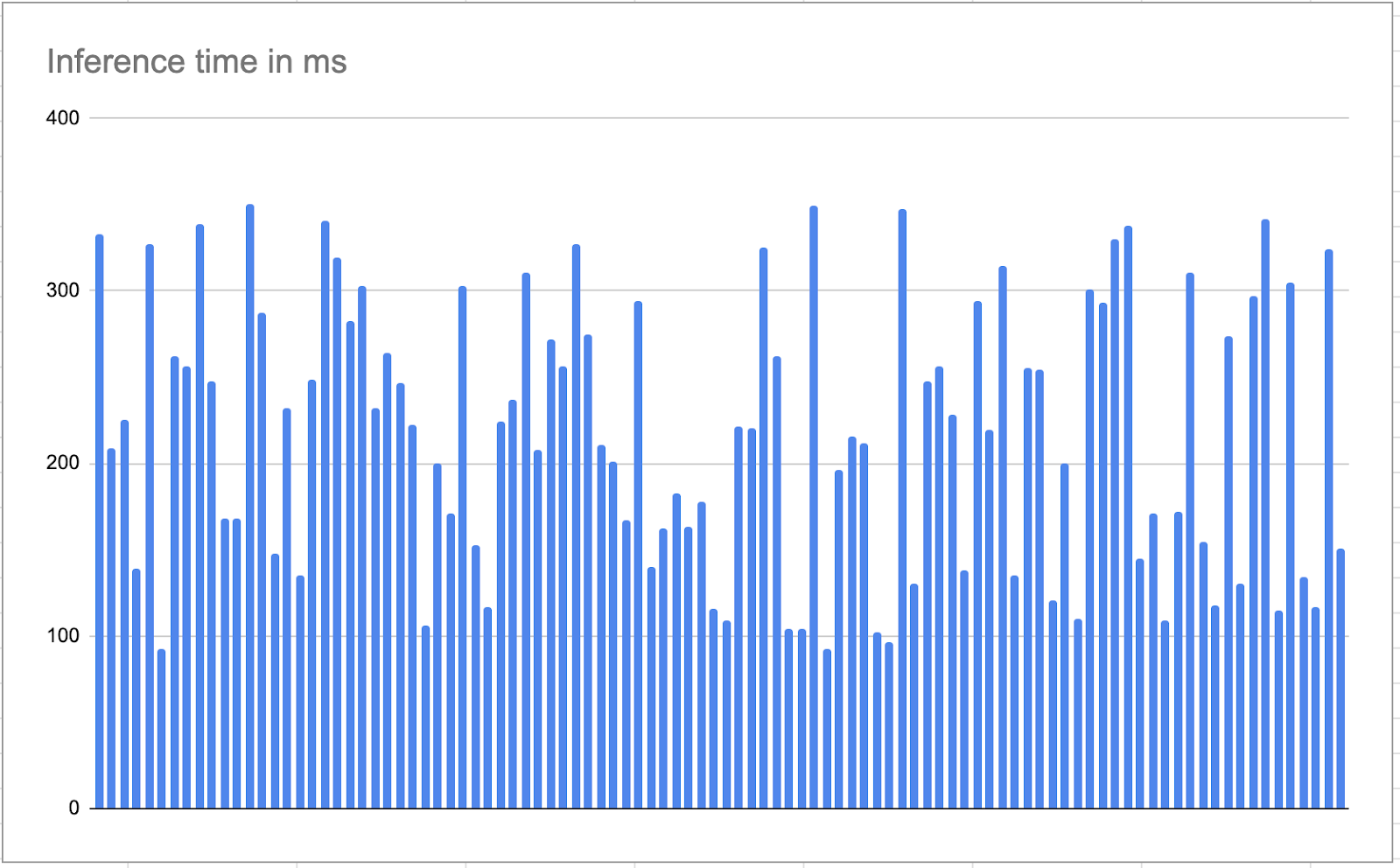
vLLM also provided us with ready-to-use chat and completion API endpoints for real-time inferencing. It also supports continuous batching of incoming requests. When we ran the evaluation with 13k records, vLLM responded with inference results in batches of 10 records.
Although it does not have an inbuilt caching layer, it is easy to implement caching on top of vLLM to improve performance.
It proved to be the best fit for the project satisfying most of our requirements.
Hosting: Modal vs AWS vs Runpod
The next step was to host it on a cloud server. Below is an insight into the different hosting platforms we explored.
Modal
Modal provides a pay-as-you-use service providing serverless hosting solutions. Serverless architecture provides the benefits of scalability and high availability with minimal operational costs along with efficient costs. We referred web endpoints document to host our code on Modal. However, it was not suitable for our use case as its cold start time was ~30 seconds.
AWS
We tried hosting the vLLM APIs on an AWS EC2 machine using the Docker Image provided by vLLM. However, the cost of the AWS GPU machine was high. So, at least for the MVP, we decided to go with a more cost-effective solution.
Runpod
We were already using Runpod to fine-tune LLMs. It provides GPU instances at a cheaper rate. These instances run on docker and hence vLLM docker image could not be used directly on the machine. We instead hosted the vLLM API as a standalone server using the supervisor daemon, a process control system. It served our purpose well for the MVP release by keeping the cost low.
(Btw, we did an interesting hackathon project for the Runpod team. Fun stuff!)
For MVP, the expected traffic on the model server was low so with a single instance of Runpod we were able to handle it. But as the traffic grows there would be a requirement to shift to a setup with multiple instances and maybe auto-scaling which is when we might plan to move to rented GPU machines.
Our hands-on experience with the vLLM library and its extensive integration capabilities has been great. Your needs for hosting and serving may vary, but we highly recommend giving it a try.



